
IT professionals are looking for scalable, flexible, affordable storage platforms for their mushrooming volumes of unstructured data. Gartner forecasts that, by 2026, large enterprises will triple their unstructured data capacity stored as file or object storage on-premises, at the edge, or in the public cloud, compared to 2022.
It’s important, then, to be clear about what object storage is and how it relates to unstructured data, so you can make smart storage decisions that will best serve your organization.
Object storage and unstructured data
 To understand the need for object storage, we first need to understand the challenge of unstructured data, which is data that doesn’t come neatly organized — in a spreadsheet, for instance — or adhere to a traditional database format. Common examples include emails, images, backups, videos, audio files and IoT sensor readings.
To understand the need for object storage, we first need to understand the challenge of unstructured data, which is data that doesn’t come neatly organized — in a spreadsheet, for instance — or adhere to a traditional database format. Common examples include emails, images, backups, videos, audio files and IoT sensor readings.
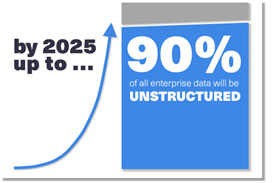
More and more data are now unstructured. In fact, analysts at IDC expect that unstructured data will account for more than 90% of enterprise data by 2026.
What is object storage?
Put simply, object storage is a type of data storage that manages data as objects, consisting of the data itself plus the object’s descriptive attributes (metadata). This is unlike other storage architectures that manage data as a file hierarchy (file systems) or as blocks within sectors and tracks (block storage). More on the differences later on.
Object storage, also known as object-based storage, offers a really simple way to store data. It organizes information into distinct containers of flexible sizes and uses keys to retrieve the specific data you’re looking for. The idea of a key is that there’s a number or an ID, similar to your Social Security number, that uniquely identifies each object. That key is used to identify or reference the value, which is the actual data, be it a Word file, an image or something else.
Object storage offers simplicity, compared to using a file system, which requires knowing what directory and sub-directory your file is in. Think about Google Drive. You have to go from your drive to the marketing folder, to the shared folder, etc.
With object storage, you don’t need to know where the data you want is located; you just provide the key. Then the system fetches your object for you.
What are the elements of object storage?
There are really just three elements in object storage:
- The previously mentioned key (the unique identifier)
- The value (the data itself)
- The metadata, which identifies descriptive properties of the object (such as when it was created, how big it is and who owns it), as well as specifies about how the object should be handled when it’s accessed.
As for metadata, custom attributes can be added to object storage systems to handle extra file-related information. By contrast, a new application and database (called “extended attributes”) would be needed to manage the metadata in a traditional storage system. Once again, object storage wins at simplicity.

Object storage = simplicity and scalability
Simplicity facilitates seamless scaling. Given the overhead of keeping track of folders and file locations within folders, there is very significant background bookkeeping and overhead involved in managing file systems. This overhead has an impact on the scalability of file systems – and that’s why file systems would never be able to store billions of files or more.
Since it has no such folder location hierarchy and instead manages objects in a simple flat model, object storage enables efficient storage, management and access to data at petabyte-scale and beyond. Object storage does keep objects grouped into logical containers (often called buckets), but this is still much simpler and less costly than a file system. It also enables much greater scalability.
What is object storage vs. block or file storage?
All of the above makes object storage fundamentally different from traditional block or file storage systems. Every object includes the data itself, as well as its related metadata, and has a globally unique key (instead of a file name and a file path). The keys are arranged in a flat address space, which eliminates the complexity and scalability challenges of a hierarchical file system based on complex file paths.
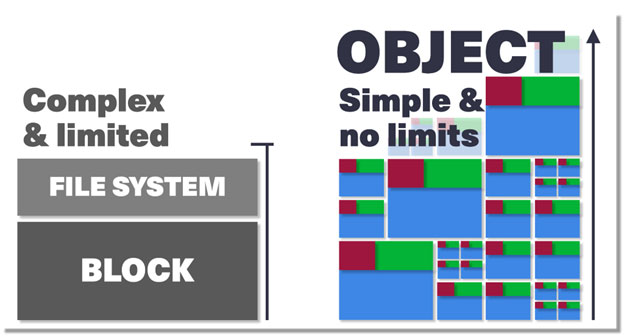
Block storage is just the raw disc capacity. For instance, back when people regularly bought disc drives from, say, a big box store, you’d get the disc and it simply had storage capacity with no formatting. There’s no structure to it. It’s just a set of fixed-size “blocks” of binary numbers, usually 4 or 8 kilobytes worth.
To make meaning out of block storage, you put a file system on top of it. A file system is just a way to organize files. Think of block storage like an empty parking lot and file storage creates the little parking spaces within that lot. To take the parking analogy a step further, object storage is the parking valet that fetches your car for you based on your ticket (the object’s key).
Scale out seamlessly with modern object storage
That’s object storage in a nutshell. Its simplicity and scalability make it ideal for organizations that have a high volume of unstructured data to store. And these days, that’s just about everyone.
Interested in learning more about why object storage is a great fit for cloud native development and how storage fits into the world of Kubernetes applications? Get the Gorilla Guide to Modern Object Storage for Cloud-Native Applications and the Gorilla Guide to Storage and Applications in Kubernetes.




