Why Hands‑on Labs?
The Veeam hands‑on lab is a completely web‑based experience, allowing you to test‑drive Veeam technologies using a simple web browser on any device. This platform provides a curated but real‑life Veeam environment that’s similar to most enterprise‑grade customer environments. The labs prepare you to address various cloud data management scenarios you might encounter and gives you confidence that you can execute your data protection strategy with Veeam solutions.
Choose Your Hands‑on Lab From the List Below!
You can filter by the following categories:
-

Advanced NAS Backup for Veeam Backup & Replication
In this lab using Veeam Backup & Replication, you will learn how to configure backup jobs for NAS and file shares.
Product: Veeam Backup & Replication
Use Cases: Data Security, Data Recovery, Data Freedom
Technical Level: Beginner, Intermediate, Advanced
With Veeam Hands‑on Lab, You Can:

Evaluate the solution without breaking anything in your local environment.

Follow a guided walkthrough to help you navigate through a set of pre‑defined lab tasks to see the business & technical value.

Test a variety of backup configuration and recovery options to prepare for deployment.
How It Works
Once you register, here’s how the Hands‑On Lab experience will work.
- Automatic Provisioning
- Confirmation
- Follow Step-By-Step Guide
- Have fun!
-
Automatic Provisioning
We will automatically begin provisioning your unique hands-on lab environment as a unique environment, dedicated to you.
-
Confirmation
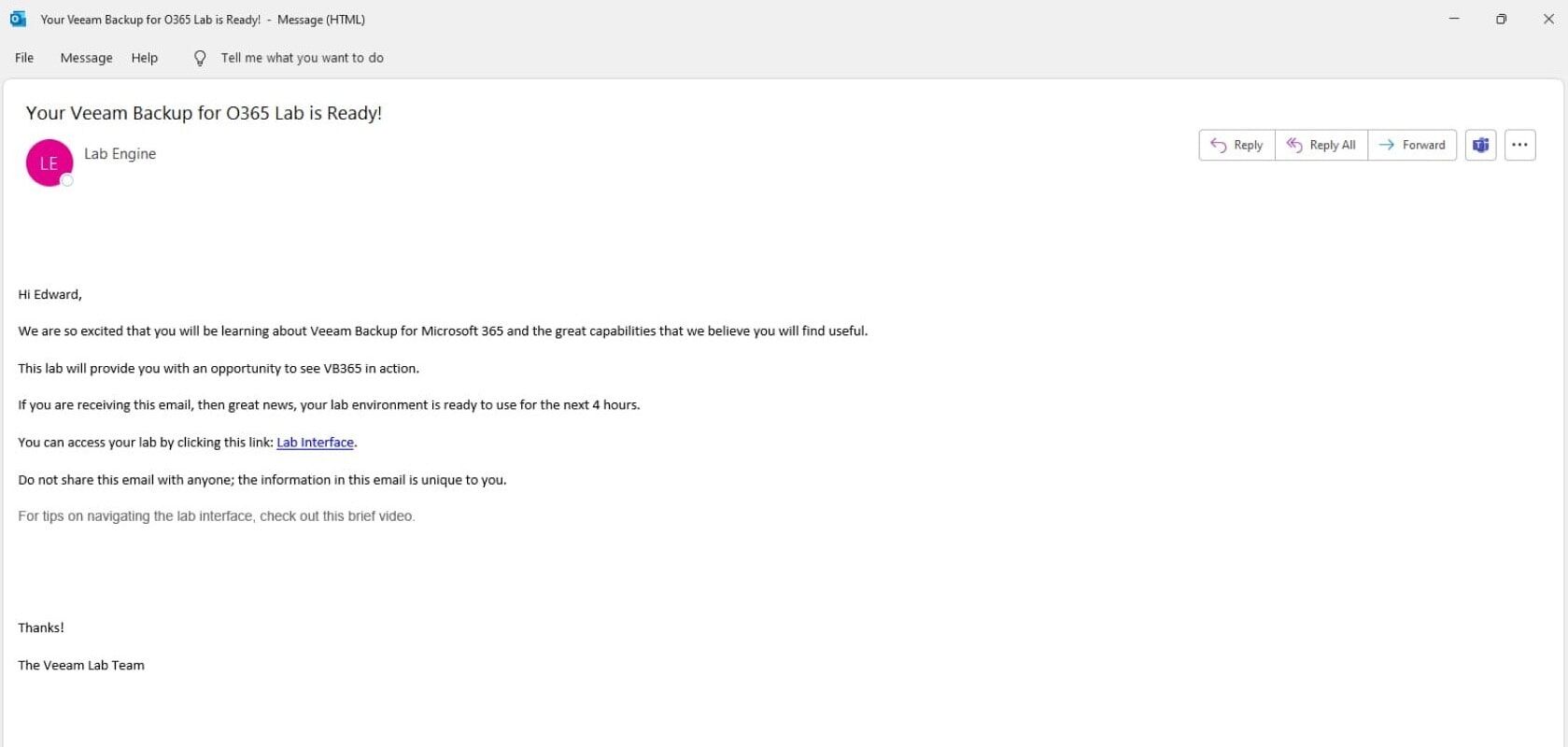
Once the lab is ready, you will receive an email within approximately five minutes with the specific log‑in instructions. Typically, each Veeam hands‑on lab will be available for up to four hours.
Click on the link in your email to get started. Please note that the email will appear to have been sent from “Lab Engine” with a subject title of “Your <lab name> is ready!”. If no email is received within five minutes, please check your spam folder.
-
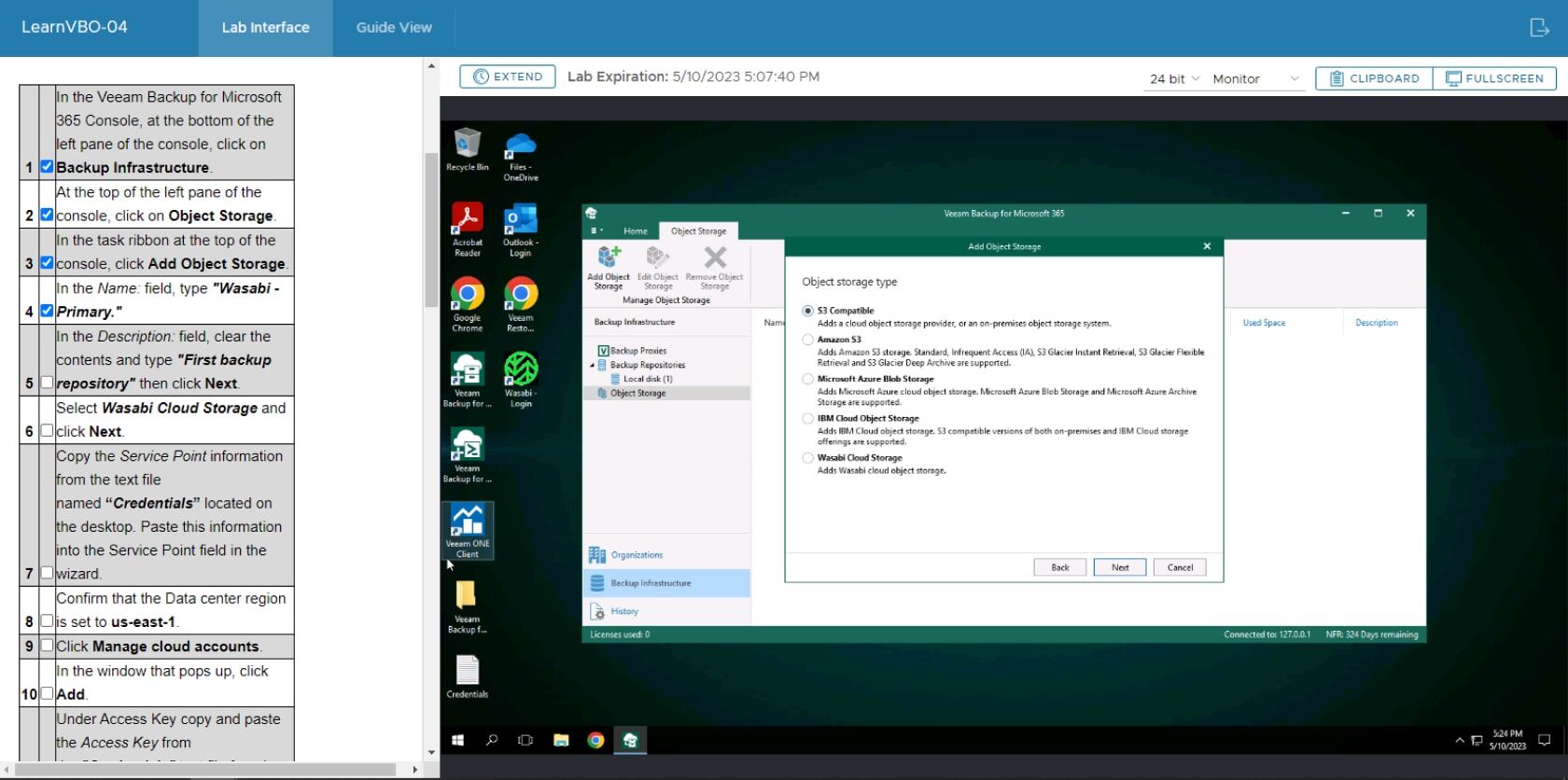
Follow Step-By-Step Guide
Upon logging in to the lab interface, you can follow the step‑by‑step guide on the left side of the screen, which will walk you through the lab activities in detail.
-
Have fun!
The lab is fully self‑contained and isolated, so feel free to explore the full potential without the worry that you might make a mistake or inadvertently affect something else.
You can re‑register anytime you wish to start a new lab.